BigQuery is quite powerful to analyze your PPC or SEO data. Databases are optimized to run JOIN statements between large tables. In this post, we’ll describe how to transform the “Problem” of Keyword Tagging or Entity Recognition that it can be handled with pure SQL within Google BigQuery. Even for big keyword lists.
Why entities are useful for keyword analysis?
In simple words: Entities are additional logical layers on top of your keywords or search terms. They will make it possible to aggregate numbers and observations.
By doing this, search patterns will appear that were long hidden before. Actually you are doing a kind of clustering on your keywords that is suited even for large data sets—we mean for GBs of data.
Getting started: Build an entity lookup list
First let’s talk about the base structure of an entity lookup list: We have some entity keys and the matching entity name. What we’ll do is to search for entity keys within the large keyword set. Whenever a match is found, the entity name is assigned to that Keyword. Let’s start with a base lookup list:
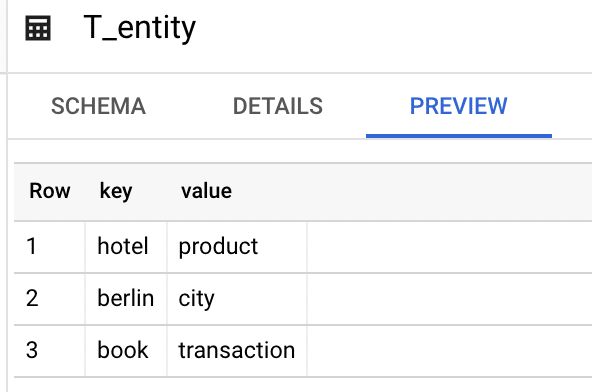
You’ll now realize that you probably have data available somewhere to enrich you Entity List. If you’re running an e-commerce shop, you’ll have a product feed—this is great for getting entities like product brand names, categories/lines, and colors or sizes. Put everything you have for your business in the table structure from above and 50 percent of the work is already done.
Enrich your Entity Lookup List – further approaches
First: The implementation of these approaches isn’t a part of this post — we’re going to share detailed posts about that in a follow up. For our consulting projects, we’re using this approaches to enrich our entity lists:
- String Similarity using Levenshtein: Based on existing entity keys in your lookup list we are checking untagged n-grams that appear in the Keyword Set we want to analyze. Here is Python Script example how you can apply string similarity.
Examples: “hotel” is very close to “hotels” (singular/plural cases) or “hottel” (Typos) - Semantic Similarity using Word2Vec Embeddings: This approach will discover semantic related entity keys which would be impossible by doing string similarity approaches. We are using the word2vec technology for discovering negative keywords within google ads, here are some more details how it works.
Examples: “hotel” is very close to “accommodation” when it comes to meaning.
Note: Our strategy is to work heavily on enriching the entity lookup list. Similarity Checks are expensive in Runtime, so you should avoid it doing it every time when you want to label a keyword set. Having a big lookup list instead makes it possible to use database JOINs which are superior in Runtime.
Labeling keywords using Google BigQuery
To run the entity labeling, we need, of course, another data source: Keywords or Queries with KPIs you want to analyze. When you’re a PPC Professional, the Search Term Performance Report is a good starting point. When you’re a SEO Professional, you might want to analyze your Search Console data with this approach. Importing the data to Big Query isn’t part of this post, but you can automate the data import to Big Query easily by using Google Ads Script or Google App Script.
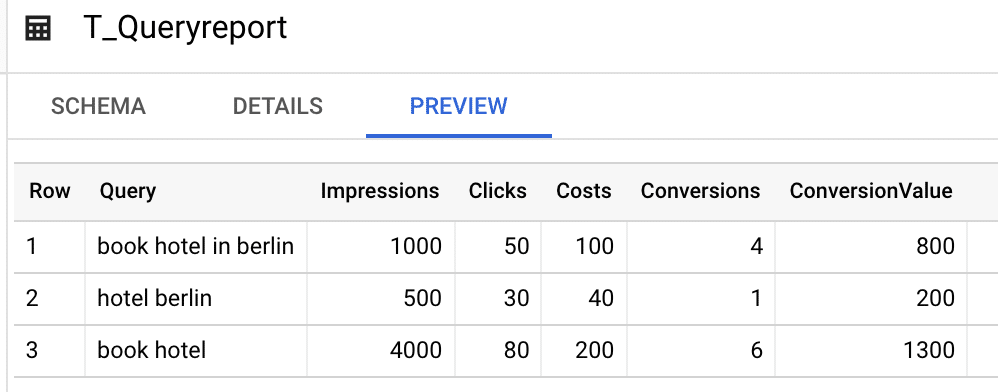
Now we have two tables in Big Query, one that contains the Keywords that should be tagged, the second table contains the label names together with the entity keys, in other words: if that test string is found in the full query, the label should be assigned.
Transforming keywords to n-grams using ML.GRAMS function in BigQuery
You’ll realize that the existing data structure will not work for using database JOIN operations for running the entity extractions. For that reason, we’re splitting the keywords into n-grams by using ML.NGRAMS within BigQuery.
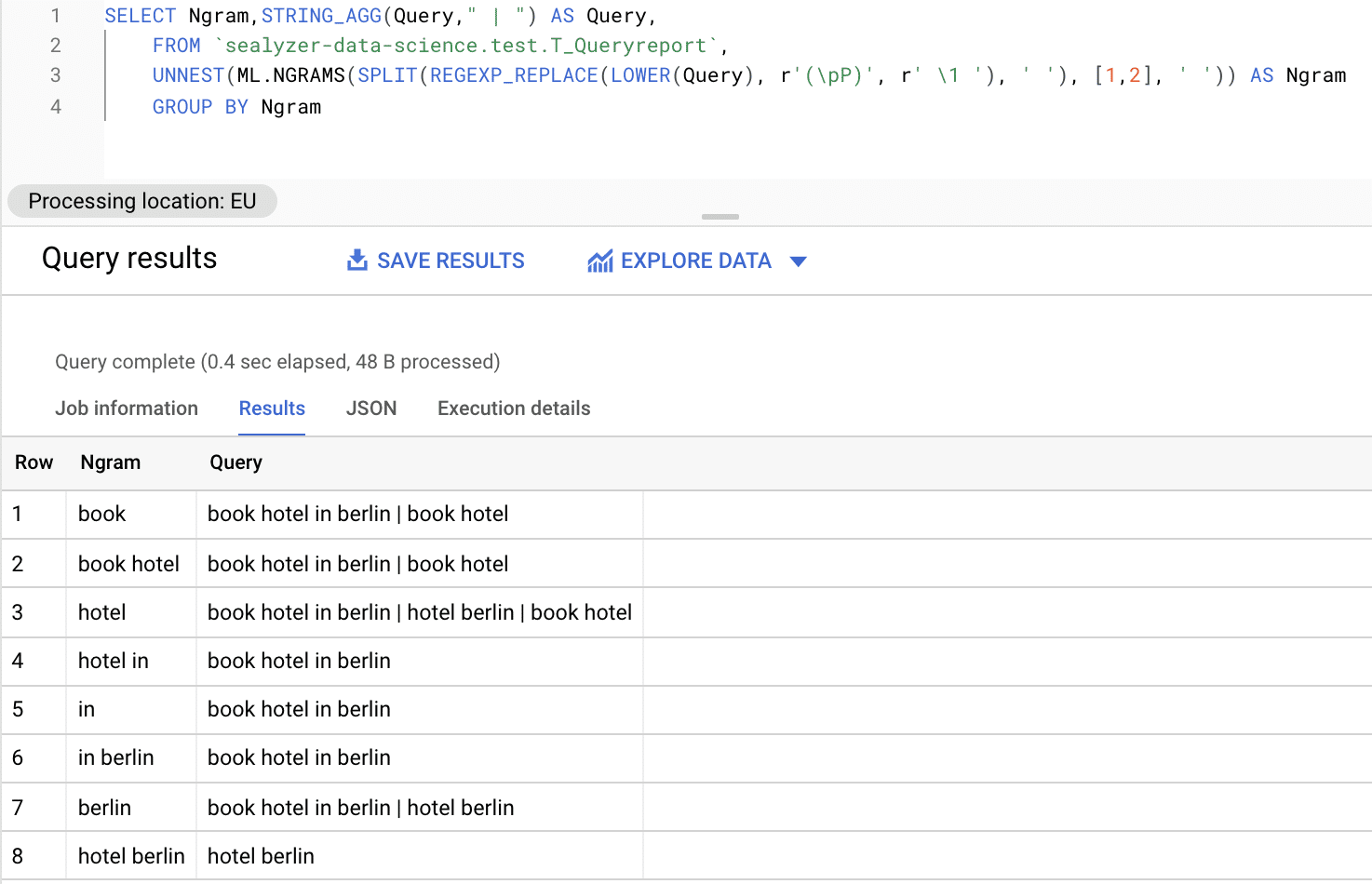
When doing this transformation, we’re splitting a single row that contains the keywords into multiple row that contain the n-gram substring of the original keywords. We used 1-grams and 2-grams. If you look at the resulting n-grams, you’ll realize that JOINS with the entity lookup table are possible now.
JOIN n-grams transformations with the entity table

Flatten the entity lookup: STRING_AGG

SELECT statement: Bringing everything together

When we put everything together and run the full query, we’re getting the desired result:

You’ll realize that there are a bunch of new columns added to the original keyword sources table:
- Entity: This column contains the found entities within the keyword. They’re combined with a pipe as delimiter. You can change that easily to your needs in the the STRING_AGG definition. If we do the tagging that way we are loosing some information, why we assigned the entity. This perspective is useful for analysis on search patterns without the need of details.
- EntityKeyValues: When details are important and you want to know the entity values. After each assigned entity the matching key is shown. Both are separated with “:” as delimiter.
- EntityKeyValuesJson: You’ll probably have some use cases that require other string transformations then we used for the EntityKeyValues column which addressing some reporting related cases. In Big Query, you can make use of JSON Extract functions, this is why we added this column. This makes it easy to create additional columns like Campaign, AdGroup, Keyword Labels that are using entity data as placeholders.
- NumberOfUnknownWords: This number tells how good the coverage of your entity list is. It makes it also possible to run some filters like: Add new Keywords to the Google Ads Account (in a specific Campaign or AdGroup) where a list of entities was found and unknown words are zero. It’ll also give you a good indication how the traffic is changing over time, e.g. google is forcing close variant matches in Google Ads.
You’ll have to adjust the SQL Code to fit to your own table structure, nevertheless It makes sense to share the SQL Code to copy and paste some code fragments:
WITH Ngram AS (
SELECT Ngram,Query,
FROM `sealyzer-data-science.test.T_Queryreport`,
UNNEST(ML.NGRAMS(SPLIT(REGEXP_REPLACE(LOWER(Query), r'(\pP)', r' \1 '), ' '), [1,2], ' ')) AS Ngram
),
ngram_entity AS (
SELECT t1.*,t2.value,CONCAT("'",t2.value,"'"," : ","'",t1.Ngram,"'") AS TagValuesJson,CONCAT(t2.value," : ",t1.Ngram) AS TagValues
FROM Ngram AS t1
LEFT JOIN `sealyzer-data-science.test.T_entity` AS t2
ON LOWER(t1.Ngram)=LOWER(t2.key)
#WHERE value is not Null
),
query_entity AS (
SELECT Query,STRING_AGG(value," | ") AS Entity,STRING_AGG(TagValues," | ") AS EntityKeyValues,
CONCAT("{",STRING_AGG(TagValuesJson,","),"}") AS EntityKeyValuesJson,
ARRAY_AGG(DISTINCT IF(value IS NULL, NULL, Ngram) IGNORE NULLS) AS RecognizedNgram,
FROM ngram_entity
GROUP BY Query
)
SELECT t1.*,t2.Entity,t2.EntityKeyValues,t2.EntityKeyValuesJson,
(ARRAY_LENGTH(SPLIT(t2.Query," "))-IF(ARRAY_LENGTH(RecognizedNgram) IS NULL,0,ARRAY_LENGTH(RecognizedNgram))) AS NumberOfUnknownWords
FROM `sealyzer-data-science.test.T_Queryreport` AS t1
INNER JOIN query_entity AS t2
ON t1.Query=t2.Query
Next steps: Interesting use cases for entity labeling in SEO and PPC
Congratulations! You have a new powerful tool in your box to make data driven optimizations. Now it’s time to apply it to some real world problems within online marketing. Here is a list of ideas where you can test this approach. All you have to do is to adjust the input columns and maybe adjust the output. It is quite simple to extract a specific list of keys within the JSON column and flatten them to additional columns:

SEO ranking monitoring based on entity patterns
You have several options here for data sources you can use. Maybe you have your own ranking monitoring tool that is collecting data for each keyword. We use Googles Custom Search API and save ranking results (Spreadsheet solution) directly in BigQuery, which makes it easy to run this analysis. In addition to that, we also recommend to store your Google Search Console data in BigQuery. The entity tagging part stays the same.
Value used for entity tagging: Keywords
KPIs: Ranking, Impressions, Clicks
Benefits: When you look on single queries you are often lost in data. Major changes in rankings and performance might be hidden. Grouping keywords together by entities will give you bigger numbers which helps you to identify new action areas.
SEO Content Analysis using Entity Tagging
Instead of Keywords you can use the URL slugs. When you also save the ranking urls of your competition, you can use the data set from above. Another good data source is the xml sitemap. You can easily extract the URL Slugs out of the sitemap with some lines of Python. To get an idea you can also use our free online tool for seo content analysis for extracting the most frequent n-grams. Now think of an extra layer on top that is extracting entities – this will give you bigger keyword clusters.
Value used for entity tagging: URL Slugs, Website Titles, Headlines
KPIs: Count of occurrences
Benefits: Knowing the high level content strategies of your SEO Competitors you can adjust your own actions. What is the market benchmark and how do they use entities to improve their SEO Rankings? Of course you can run the same analysis with your own content and compare with your competition and look for the main differences and gaps.
Value prediction models using entity features
This is our favorite one and we’ll share a deep dive on building machine learning models within BigQuery soon. Every prediction model needs features—and maybe you have realized that in the SQL Code we used ML.GRAMS to create n-grams – this is very common to create features out of text. Our approach is even more powerful: using structured entities tailored to your business will result in superior models.
Next Question: what does “Value” prediction mean? In PPC Context, you can predict Conversion Rates and Average Order Values. This will give you an estimated VPC (Value Per Click) that is most you need to set manual CPC (Cost Per Click) Bids in your Google Ads account based on your targets. With a big entity list, you can create superior bidding models compared to Google’s smart bidding. By knowing your business, you can enrich your keywords with entities that will give you more observations and better models to judge the longtail keyword performance.
Model Features: Entity Keys and Entity Values of PPC Search Terms
Target Variable: PPC Transactions, PPC Order Values
If you have the situation in your company where you have high spending SEA Department, you should use this approach to prioritize your SEO activities. In the end, it isn’t about ranking gains or traffic growth. It’s about the value of traffic for your business.
Now we can already hear some SEO Professionals screaming: You can’t focus on transactional content only. There are more stages before a transaction will happen. You’re right. Let’s model it. The features are staying the same, but we have to adjust the target variable:
Our target is now based on the user coming back to our website after some time. Let’s say in a time window of 90 days. You can extract that data on client ID / URL Level in Google Analytics. Use e.g. the URL, Headlines or Titles to extract the entity features and create a prediction model that gives you the probability that the top of funnel content will give you returning users. The feature importance (entities and entity keys) will give you a great way set the right focus on our SEO activities.
Model Features: Entity keys and entity values of page content (URL, Title, Headlines)
Target Variable: Returning user within X days time window
When you start brainstorming, you’ll find a lot of additional use cases for your business. One more thing: It’s easy to build a nice Google Data Studio dashboard that is making use of our entity insights.