
Keyword Tagging
Need relevancy in keyword topics? Understand what the users search for.
The keyword research process in SEO and SEA made a wide stride with “recognition”. It helps identify and categorize entities, in other words, key information in a text. Google’s “refine keywords” option in keywords planner works with this idea it works out nice for some keywords, but it shows no found entities for others. In particular, it frequently happens on rare words that are mainly used in your business domain. However, there are approaches for you to build your own perfect working solution.
From Tagging to Keyword Topics
Before creating your perfect holistic SEO landing page, try to understand what the users are searching for.
WHAT IS KEYWORD TAGGING OR NAMED ENTITY RECOGNITION?

- Think of a long list with signal words like “buy”, “shop”, “order” that is mapped to a speaking name for that group — in our example a good name would be “transaction”. You’ll already have a good idea of which tag categories fit your business. By running a large keyword list against a long lookup list of signal words and different tag categories, you’ll get new insights that were hidden before.
- You can do this in Excel for smaller projects with some scripting, but it doesn’t really scale well. In our solutions, we use machine learning approaches running in Python. Let’s look at the whole process.
WHEN YOU SHOULD USE TAGGING IN YOUR KEYWORD RESEARCH?
You have no idea about the keywords: Clustering,
N-Gram Analysis
When you’re new to a business and have no idea how users conduct their searches, it’s challenging to start with keyword tagging. First, you’ll need a plan about the most important categories to define logical lookup lists. For that reason, you should start with keyword clustering techniques or N-Gram analysis to get a basic understanding of keyword topics.
You already have an idea about your keyword topics: Keyword Tagging
If you already know some of your keyword topics, you can start right away, defining your lookup lists. We highly recommend using N-Gram Analysis and starting with the words that have the highest word counts. It’ll give you the best keyword tagging coverage in a short time. Let’s try our free N-Gram analyzer tool!
HOW TO BUILD A LOOKUP LIST FOR THE TAGGING PROCESS
Build your own entity database
Build a centralized entity database for your business. Don’t just use it for tagging your keywords. Think of applying it on SERP snippets or your competitors’ content.
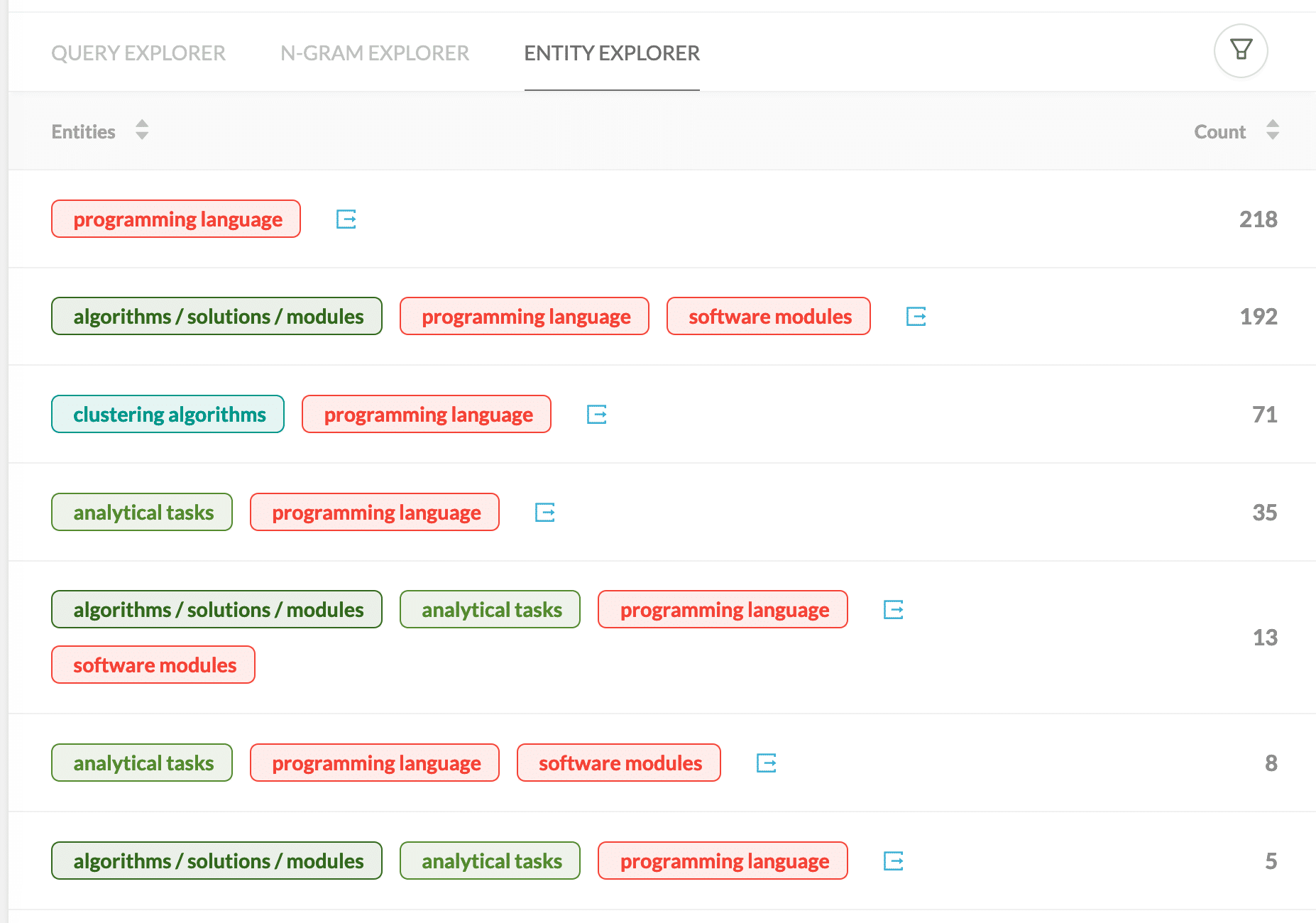
Keywords grouped by Entity Tags
Entity Recognition applied on a keyword list. You can also use additional metrics like search volume in addition to the keyword count.
1) Use existing data feeds
If you have a product feed available, you can start copy and paste right away. If not, you probably already have a logic for your site and a URL structure where you can find information about tag categories.
2) Start adding tag categories
Do you already know which keywords are the most popular in your business? Let’s use this knowledge and start adding tag categories that come to your mind with some signal words. — No need for a perfect list at that stage.
3) Categorize N-Grams
Try to free N-Gram tool for free with the highest search volumes to the existing tag group. By doing this, you’ll get the best coverage of tagged search queries as soon as possible. We’re sure you’ll find many new categories with this process — add them to your lookup list.
4) Add close variants and semantic similar words
At that stage, you can use the existing lookup list and look for similar words within the untagged words. Regex functions and string distance metrics will add a lot of new lookup keys to your list. Have a look at the Python module FuzzyWuzzy that uses Levenshtein distance for string similarity.
5) Add semantic similar words
It’s the “wow” moment for most people. If you create word embeddings with word2vec on your complete keyword set, it’s possible to search for semantically similar words. If you have an entity “color” with one value “green,” the word2vec model will show you “red” and “blue” as similar semantic words. It’ll boost your list size.
HOW TO USE YOUR ENTITY DATABASE FOR KEYWORD TAGGING
Avoid RegEx or String Similarity Comparisons
Regular impressions are costly in computation time when you process large keyword files. We used them for setting up our tag category database. The same problem occurs when you’re using similarity algorithms like Levenshtein. We used those approaches once for defining our lookup lists. By doing so, we can use Python dictionaries for all the tagging. It’s blazing fast.
Use Dictionaries or Flash Text for lookups
There’s a great Python module out there called Flash Text. You can use it for the keyword tagging process. Load your lookup database into the Keyword Processor and start extracting entities. It’s all about speed — maybe other approaches are ok when making lookups for 100,000 keywords. However, think of 100,000 website pages you want to tag with our entity database — now you’ll realize whether your solution scales or not. If you’re interested in the Flash Text algorithm have a look at here.
Go Parallel in your processing
If speed is crucial for you or the datasets are huge, think of splitting the tagging process to multiple worker scripts. When you publish your Python solution to Amazon, Lambda or Google Cloud functions, you can easily use those scaling approaches.