Analyzing the content of your competitors can provide you with valuable insights about your own operations and goals. This basic Python script can give you information on N-rams in seconds.

How to analyze your competitors’ content with Python script
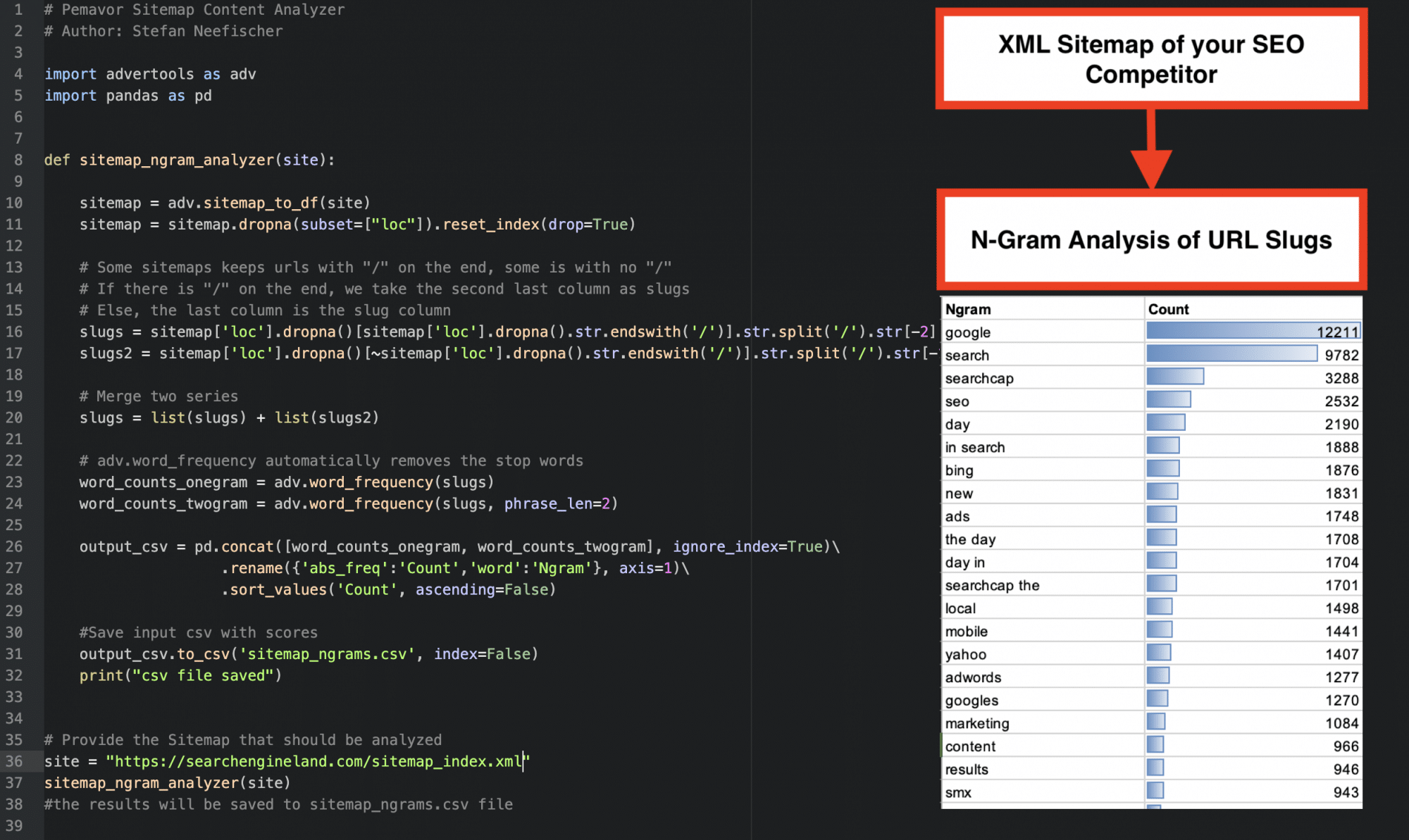
This Python script is a basic version of a content analysis of your competitor. The main idea is to get a quick overview of what the writing focus looks like. A lean approach is to fetch all URLs in the sitemap, parse the URL slugs and run an n-gram analysis on it.
If you want to know more about n-gram analysis, please also have a look at our Free N-Gram Tool. You can apply it not only for URLs but also keywords, titles, etc.
As a result, you’ll get a list of used n-grams in the URL slugs together with the amount of pages that used this n-gam. This analysis will only take a few seconds even on large sitemaps and will run with less than 50 lines of code.
Additional approaches
If you want to get deeper insights, I can recommend going on with these approaches:
- Fetch the content of each URL in the sitemap.
- Create n-grams found in headlines.
- Create n-grams found in content.
- Extract keywords with Textrank or Rake.
- Extract known entities for your SEO business.
However, let’s start simple and take a first look into the rabbit hole with this script. Based on your feedback, we may add some more sophisticated approaches. Before running the script, you just need to enter the sitemap URL you want to analyze. After running the script, you’ll find your results in sitemap_ngrams.csv. Open it in Excel or Google Sheets and have fun with analyzing the data.
Bonus Tip:
If you run it twice—once for your competitor and once for your own sitemap—you can easily create a Gap-Analysis within Excel.
Here is the Python code:
# Pemavor.com Sitemap Content Analyzer
# Author: Stefan Neefischer
import advertools as adv
import pandas as pd
def sitemap_ngram_analyzer(site):
sitemap = adv.sitemap_to_df(site)
sitemap = sitemap.dropna(subset=["loc"]).reset_index(drop=True)
# Some sitemaps keeps urls with "/" on the end, some is with no "/"
# If there is "/" on the end, we take the second last column as slugs
# Else, the last column is the slug column
slugs = sitemap['loc'].dropna()[sitemap['loc'].dropna().str.endswith('/')].str.split('/').str[-2].str.replace('-', ' ')
slugs2 = sitemap['loc'].dropna()[~sitemap['loc'].dropna().str.endswith('/')].str.split('/').str[-1].str.replace('-', ' ')
# Merge two series
slugs = list(slugs) + list(slugs2)
# adv.word_frequency automatically removes the stop words
word_counts_onegram = adv.word_frequency(slugs)
word_counts_twogram = adv.word_frequency(slugs, phrase_len=2)
output_csv = pd.concat([word_counts_onegram, word_counts_twogram], ignore_index=True)\
.rename({'abs_freq':'Count','word':'Ngram'}, axis=1)\
.sort_values('Count', ascending=False)
#Save input csv with scores
output_csv.to_csv('sitemap_ngrams.csv', index=False)
print("csv file saved")
# Provide the Sitemap that should be analyzed
site = "https://searchengineland.com/sitemap_index.xml"
sitemap_ngram_analyzer(site)
#the results will be saved to sitemap_ngrams.csv file
Do you need a custom Python script?
With our experienced Python developers, you can bring your ideas to life. We understand the power and flexibility of Python. Contact us today. And let’s discuss how we can help you.